Speaker-independent Standard Dataset Partitions
We include 6 public emotion datasets in EMO-SUPERB. (1) IEMOCAP (2) CREMA-D (3) MSP-IMPROV (4) MSP-PODCAST (5) BIIC-NNIME (6) BIIC-PODCAST. We provide standard partition for IEMOCAP, CREMA-D, MSP-IMPROV, and BIIC-NNIME datasets that lacks official splits. These partitions prevent the data leakage problem and provide a fair comparison for SER.
IEMOCAP
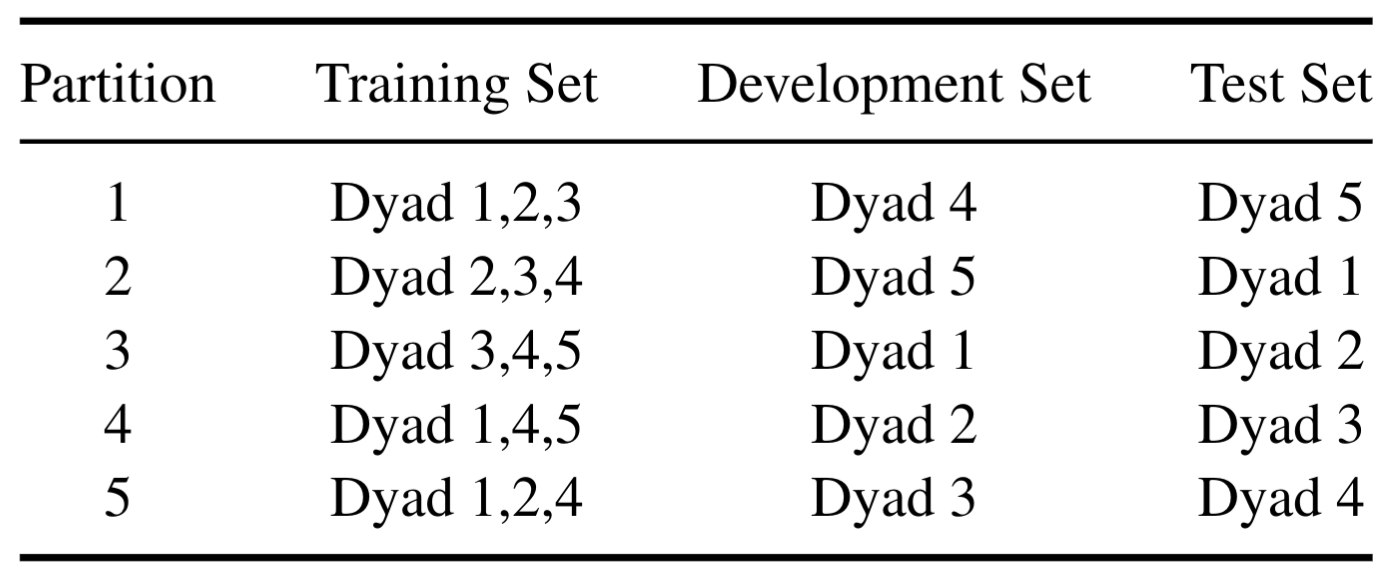
We define five speaker-independent splits (i.e., Dyad 1 to Dyad 5) for cross-validation. Each session consists of two speakers engaged in dyadic interactions.
MSP-IMPROV
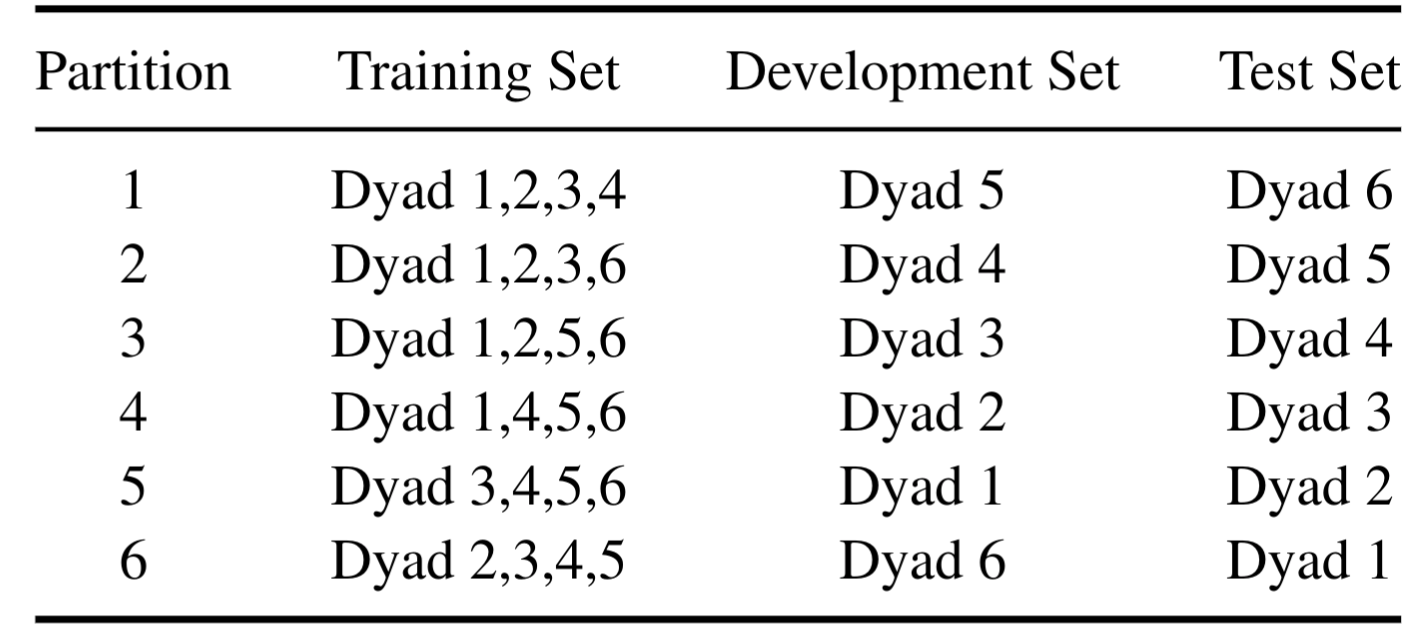
The MSP- IMPROV corpus is partitioned into six folds for cross-validation.
CREMA-D
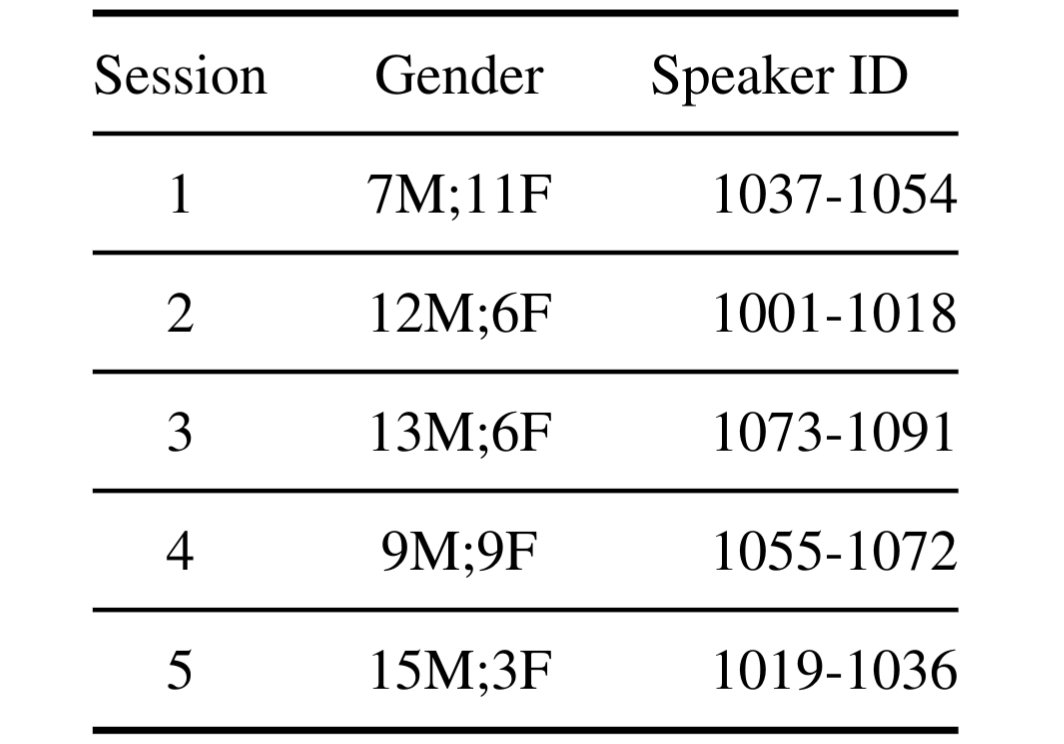
The CREMA-D corpus is divided into five sets based on speaker IDs. Each set consists of a different combina- tion of male and female speakers, as well as a distinct range of speaker IDs.
BIIC-NNIME
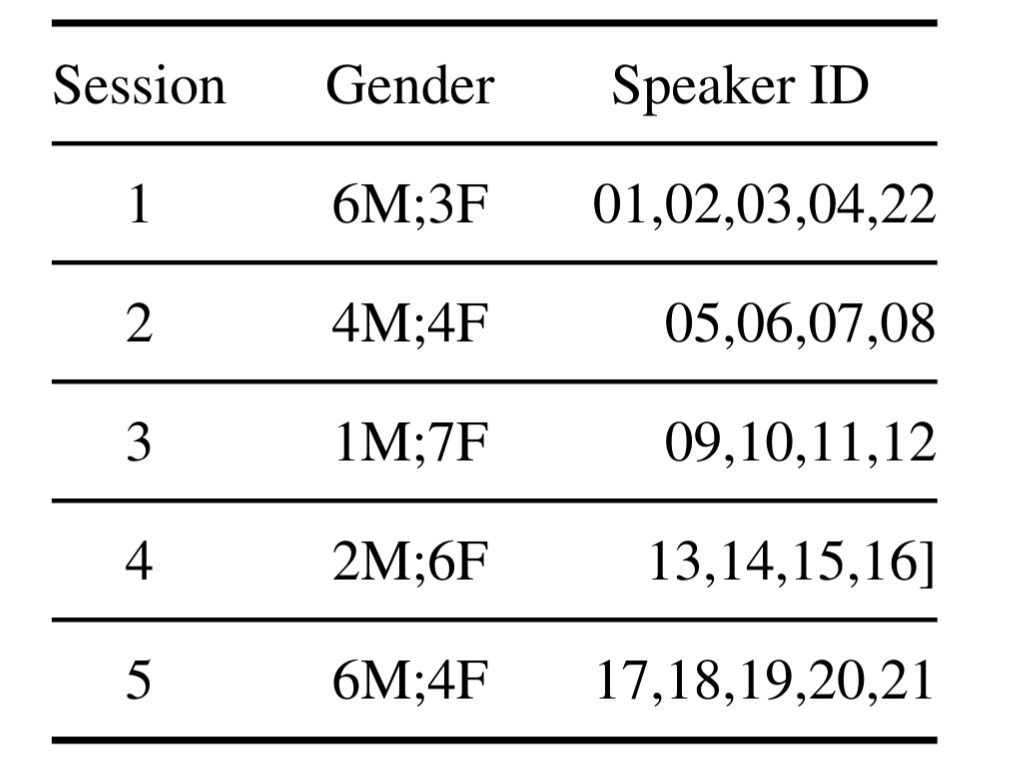
The NNIME corpus is randomly split into five sets based on speaker IDs. Each set comprises a different com- bination of male and female speakers, as well as a distinct set of speaker IDs